Most AI coverage fixates on how well models chat, but this piece from NO BS AI makes a far more consequential claim: the real breakthrough isn't conversation, it's the ability to execute code. The article shifts the focus from generating text to triggering actions, arguing that without mastering function calling, large language models remain little more than sophisticated parrots. This matters now because the industry is pivoting from passive assistants to active agents that can book flights, query databases, and manipulate software without human intervention.
The Architecture of Action
The editors begin by dismantling the standard narrative of how these models are built, noting that "Large language models like ChatGPT can follow instructions because they've been trained to do just that." They break this down into a three-step evolution: base training for language comprehension, instruction tuning for helpfulness, and finally, the critical leap to tool usage. The piece argues that "if we want to build something more powerful—like an AI Agent that can do things for you... we need to teach the model how to use tools." This distinction is vital; it separates the current generation of chatbots from the next generation of autonomous workers.
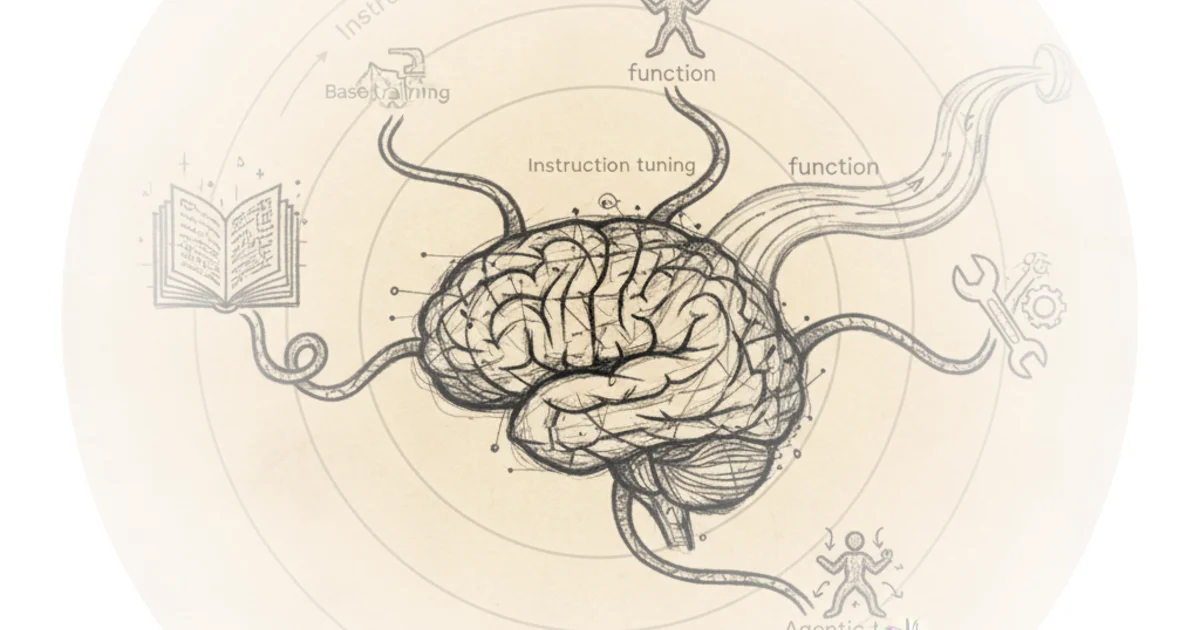
The core challenge, as the article explains, is that a model must not only recognize a user's intent but also map that intent to a specific piece of software. "From the model's point of view, this is how it 'uses Google,'" the text notes, describing the process of calling a function like `search(query)` with precise parameters. The editors emphasize that this isn't magic; it requires specialized datasets where the model learns to recognize that an instruction like "Find the latest Booker Prize nominees" should trigger a specific function call with the correct arguments. This reframing is effective because it demystifies the "agent" concept, revealing it as a rigorous engineering problem of data mapping rather than a sudden leap in intelligence.
Just like humans use apps, LLMs can use tools by calling functions—little blocks of code with parameters that tell the tool exactly what to do.
The Data Dilemma
Where the coverage becomes most valuable is in its granular look at the data construction process. The author, writing from experience with the Bielik team, admits that "even though there's a lot of research out there, it's hard to find clear, step-by-step explanations of how people actually do it." This transparency is refreshing in a field often shrouded in marketing hype. The piece details the struggle to find high-quality function descriptions, noting that public datasets like RapidAPI often contained "unclear or poorly written" descriptions that would confuse a model.
To solve this, the team turned to the Argilla project, translating functions into Polish and accepting that "having imperfect data can actually help the model become more flexible." This is a nuanced take on data quality; perfection isn't always the goal if it stifles the model's ability to generalize. The editors then describe a clever workaround for generating the hundreds of thousands of instructions needed: using another language model to create the training data. However, they quickly identify the trap of homogeneity, where models tend to "give similar answers if you ask the same thing repeatedly."
The solution offered is a creative injection of diversity through "Personas." By instructing the data-generation model to adopt specific identities, the training set becomes richer and more realistic. The article illustrates this with a striking contrast: a "local priest" asking for facts about a papal visit versus a "bohemian artist" inquiring about summer concerts. "That variety makes a huge difference when training a model that's supposed to understand a wide range of people," the piece concludes. This approach highlights a critical insight: for AI to be truly agentic, it must understand the context and voice of the user, not just the literal command.
Critics might note that relying on synthetic data generated by other models risks compounding biases or creating a feedback loop where the training data only reflects the limitations of the generator. However, the article acknowledges this by emphasizing the need for diverse personas to break the pattern of repetition.
Real-World Scenarios and Quality Control
The final section of the coverage tackles the complexity of real-world application. The editors stress that a robust dataset must include edge cases, such as instructions where "no tool is needed" or situations requiring the model to "choose between similar tools." They draw inspiration from the Berkeley Function Calling (BFCL) dataset to ensure the training covers scenarios where a model must distinguish between `insert_record` and `update_record`. This attention to nuance is where the piece separates itself from superficial overviews. It acknowledges that the hardest part of AI isn't the happy path; it's handling the ambiguity and errors inherent in human requests.
The editors wrap up by reinforcing that scale is not a substitute for precision. "But quantity alone isn't enough—quality is absolutely critical," they state, noting that their entire dataset underwent a "careful and thorough verification process." This commitment to validation is the strongest signal in the piece that the industry is maturing from experimental prototypes to reliable infrastructure.
That variety makes a huge difference when training a model that's supposed to understand a wide range of people.
Bottom Line
The strongest part of this argument is its practical deconstruction of how to build reliable AI agents, moving beyond theory to the gritty reality of dataset engineering. Its biggest vulnerability is the reliance on synthetic data generation, which, despite the use of personas, may still struggle with the chaotic unpredictability of actual human interaction. Readers should watch for the promised follow-up on the quality-checking pipeline, as that will likely determine whether these agents can be trusted in production environments.